By Silas Rudolf
Within the last few years, speech recognition has seen vast improvements. Widely known systems like Siri, Alexa and Google Assistant have made it into our living rooms and are part of our everyday lives. In this article, we will take a closer look at how speech recognition can be done and in particular, how automatically transcribed text can be realigned with its original audio after correction.
Although all these Automatic Speech Recognition (ASR) systems rely on slightly different technical processes, the main steps for all of them is the same:
- Capture the vocal input.
- Run the voice data through an acoustic model, optionally transcribe the audio to other formats such as phonetic representations.
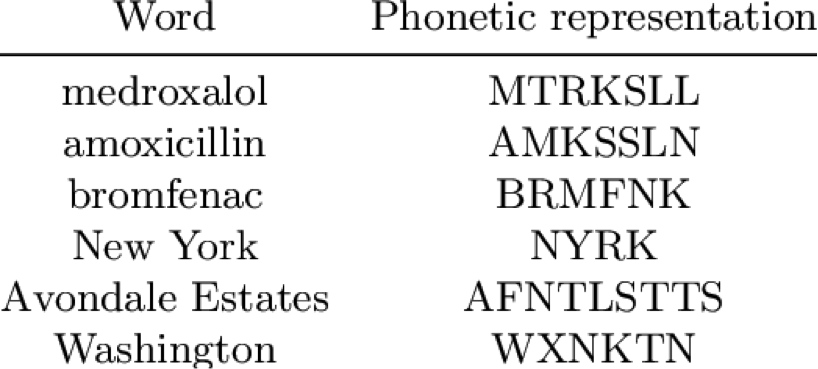
- Process the phonetic parts with a language model. A language model is basically a statistical distribution model that predicts the order in which words are most likely put together.
- Output text data.

Today, these ASR systems can achieve accuracy rates of up to 95 percent. They can also provide a timestamp for the occurence of each word in the audio file, which can be extremely useful for providing audio-aligned transcripts.
However, if you depend on high-quality texts for tasks like interview transcriptions you will want to review and correct the transcriptions produced from the recognition software.
Let’s look at an example audio.
Here is how the transcription could look like from one of the ASR systems.

Now, in most cases the transcription has to be reviewed and corrected.

Depending on the quality of your recording and the number of speakers, the corrections can range from very minor to, in some cases, incorrectly transcribed sentences. Thus, changing the entire meaning of the sentences.
As a consequence, some of the timestamps could get lost in the correction process, or not be accurate with the newly inserted word. This can make it hard to have a solid alignment between the transcription and the original audio file.
Which brings us to the main question:
How can we estimate the timestamp of a corrected transcript for audio-alignment?
For the following experiments, we will be using the NIST Meeting Pilot Corpus Speech corpus, which has approximately 15 hours of English meeting speech (from 19 meetings), together with word-level transcriptions, including timestamps. It was collected in the NIST Meeting Data Collection Laboratory for the NIST Automatic Meeting Recognition Project.
We will look at three important steps:
- Analysing the data set
- Normalisation and feature extraction
- Modelling of the timestamp correction
Analysing the Data Set
Before we begin with using different modeling approaches, it is crucial to have a general overview on what data we are working with.
It will give us an idea of:
- How the data is structured, with first estimates and summaries
- The distribution of our data
- Potential outliers and typos, unexpected patterns and observations that need to be considered while moving further
And most importantly, we can make sure that the data Is appropriate for the task we are trying to achieve.
Let’s start checking how many words and speakers we have in our dataset:
| Total words | 653’466 |
| Unique words | 3’119 |
| Speakers | 52 |
Interestingly, the total vocabulary size of unique words is only at a bit more than 3’000 words. This tells us that the speech is probably on a daily conversation level (most of the everyday english conversations can be understood with a vocabulary of about 2500-3000 words)
Within this vocabulary, what do you think are the words most commonly used?
The following chart shows the top-100 words ranked by the number of occurrences:
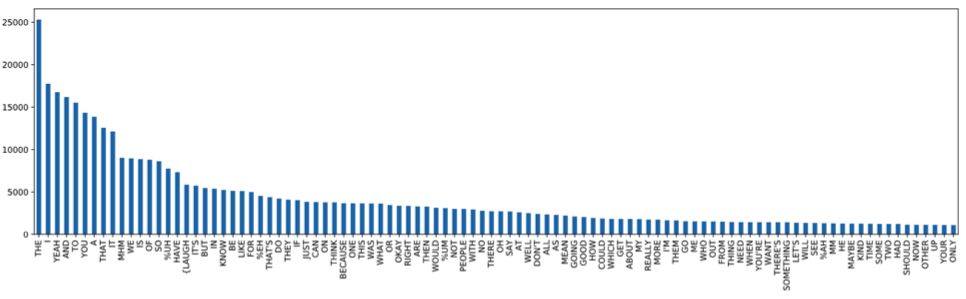
At the head of the list, we have many so-called stopwords, which are basically a set of commonly used words in any language. (https://www.ranks.nl/stopwords)
Removing the stop words can, in some cases, already give some insights on the general direction of the conversation of the meeting. Can you spot what it was about?

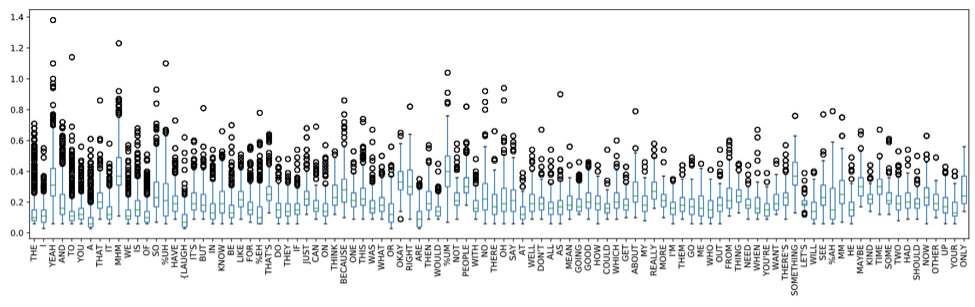
As we are interested in estimating the timestamp, it is also helpful to look at how long it takes a speaker to utter those words.
For those of you who might not be familiar with boxplots, the important things to look out when interpreting this chart are:
- The Median: the “middle” value or midpoint, represented by the line inside of every box
- The Interquartile Range: A measure of where the majority of the values lie, represented by the edges of the box. The lower part being the 25% quartile, the top the 75% quartile.
For more information, check out this article.
Quite some words have a high variability in their length, ranging from 0.1s up to 1.4s.
We can also have a closer look on the distribution of the utterance-length of some of the words.
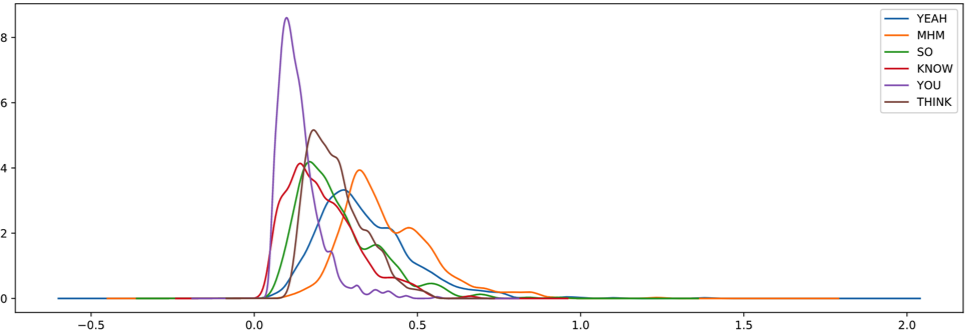
This shows us that even if words have the same amount of syllables, their utterance-length can be very different.
Before we go to our key takeaways from this first analysis, let’s look at the speaker perspective. Here, one of the interesting metrics is the individual words-per-minute (WPM) speaking rate.
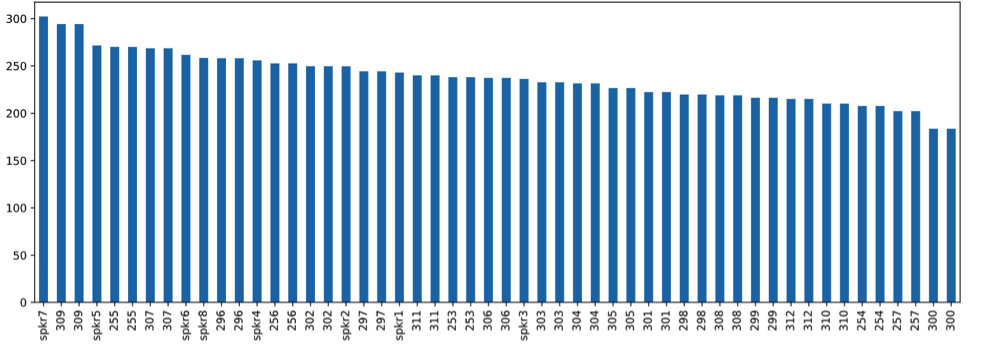
Of our 52 speakers, we have a WPM range between 183 and 302, which can already give us some hints of what features can be important to model.
What have we learned so far that can be used in the proceeding steps?
- Words that have a similar character-lengths can have different utterance-lengths.
This means that we cannot only estimate timestamps of a word from its number of characters.
- Different speakers have a different pace of speaking. For modeling this can be an important takeaway to use as potential feature
Normalisation and Feature extraction
Computers have difficulties working with text directly, but they work exceptionally well with numbers and vectors. So before we can test different approaches on estimating the timestamps with the information we have gathered so far, the words have to be transformed into something a computer can understand.
One common approach is to convert text to a vector of numbers, that is then used in further processing.
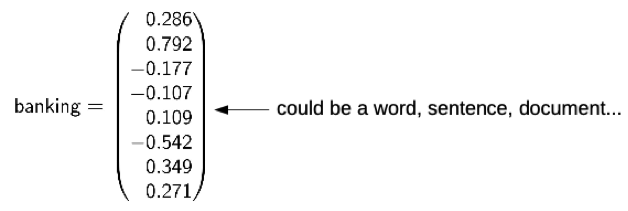
At a very high level, the key idea here is to use the surrounding words or context, to score each word with some kind of distance measure (word embedding).
This distance score can then be used from the model to find similarities and differences between words.
Using this to transform the words in our corpora leads to an embedding matrix of shape (653’466, 96).
- 653’466 columns representing the individual words
- 96 rows representing the distance score of each word
Modeling
With our words converted into vectors, we can now start predicting their timestamps within a sentence (length of their pronunciation).
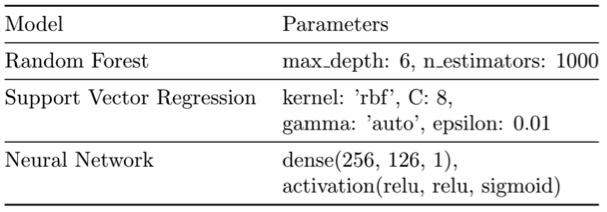
We will be using three different Machine Learning methods and compare their individual performance:
- Random Forest (RF)
- Support Vector Regression (SVR)
- Neural Network (NN)
The models with their respective parameters can be seen in the table below and are kept fixed across all the following experiments.
Results
First we train the model on the whole corpora (general) and compare it with training on individual speakers.
To measure the error rate we use the absolute offset in seconds between the predicted timestamp and the actual timestamp.
As a baseline, the median WPM rate of each speaker is used.

| Error general model(mean) | Error individual model(mean) | |
| Random Forest | 0.20s | 0.06s |
| Support Vector Regression | 0.18s | 0.05s |
| Neural Network | 0.26s | 0.05s |
| Baseline (WPM) | 0.12s |
Here we can notice that, if trained on the general corpora without taking the speaker into account, all models perform very poorly.
With speaker-specific training however, the mean error can be lowered to 0.05s – a very good result.
Now going into specifics, we could check which words produced the highest error rates when predicting the timestamp:

If you go to one of our first charts, This result corresponds to the variability in utterance-length of the most spoken words.
With the most error prone word “YEAH”, we see that it has a median length of 0.3s and a peak outlier at 1.4s, which explains the high error .
Looking back, we achieved some good results with speaker-specific training. In the future, there are even more possibilities to explore, which can possibly further improve our model, such as:
- Providing more contextual information by passing the surrounding sentence into the model
- Passing timestamps of surrounding words into the model
I hope this information was useful and gave you some insights about timestamps in ASR systems.
If you want to learn more about audio and text analysis, check out our other articles.